CASE STUDY
Storytrack — Designing a decision clarity layer for product teams
Storytrack helps teams preserve the “why” behind product work as a structured narrative timeline — so the answer to “why did we do this?” doesn’t depend on who’s still in the room.
The problem worth solving
In most organisations, decisions don’t vanish — they fragment.
A research insight lives in a slide deck. A trade-off is buried in Slack. A stakeholder conversation gets summarised differently by three people. Weeks later, when someone asks “why did we ship it this way?”, the team either:
- re-litigates the decision (wasting time and reintroducing bias), or
- reconstructs a plausible story from memory (which quietly becomes “truth”).
“That isn’t a documentation problem. It’s a retrieval problem.”
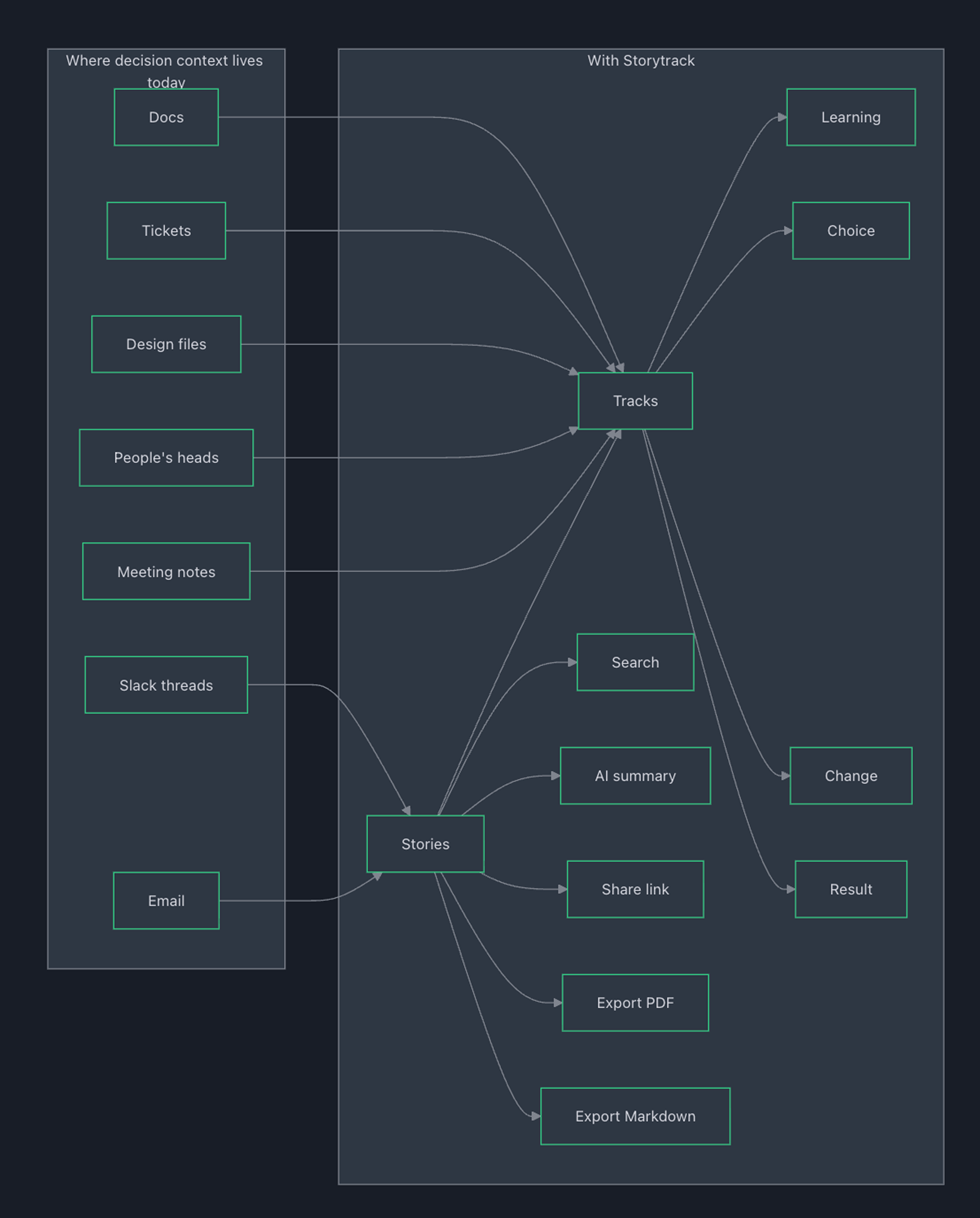
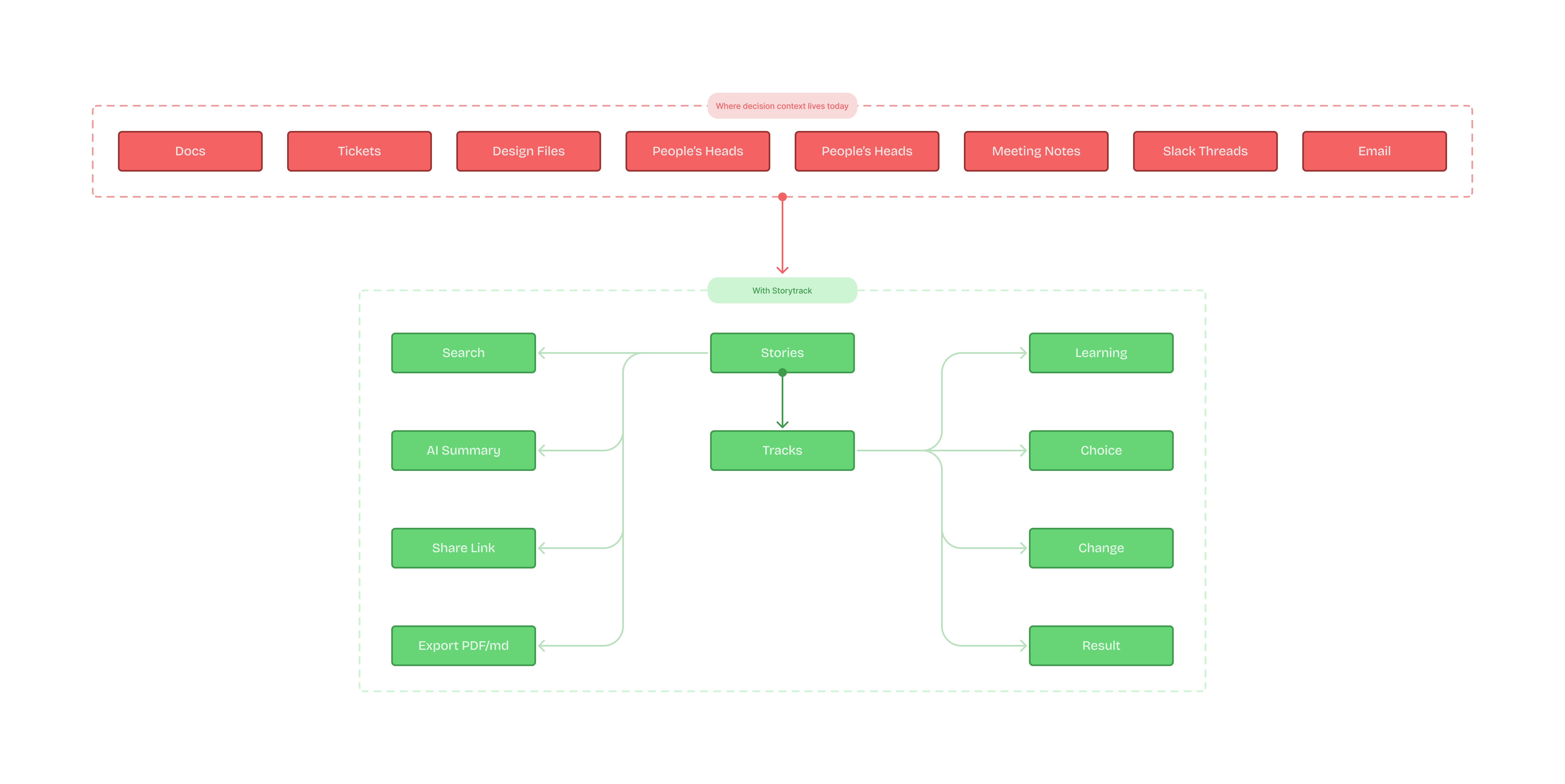
Most tools are optimised for writing (blank pages, rich formatting, infinite flexibility). But the real pain shows up later — when a new joiner, stakeholder, or even the original team needs to reconstruct causality: what we learned → what we decided → what changed → what happened.
Storytrack is my attempt to solve that specific gap: a lightweight way to capture turning points as they happen, and retrieve them later as a coherent narrative — not a folder of artefacts.
Discovery: conversations that shaped the brief
Product Director
Regulated Enterprise
- Existing "decision logs" had inconsistent adoption.
- Critical context lived in heads (key-person risk).
- Needs: Low-friction capture, secure sharing.
Startup Cofounder
Due Diligence / Acquisition
- Teams dug through months of emails to prove decisions.
- "Forensic work that shouldn't be forensic."
- Need: Structured timeline to collapse reconstruction time.
Enterprise Strategist
“We already use Confluence”
- Clarified the real competitor: status quo habits.
- Differentiation must come from retrieval speed.
- If it's just "another wiki", it fails.
My role and constraints
I built Storytrack as a solo founder, wearing the Senior Product Designer hat end-to-end: I defined the product model, information architecture, flows, interaction patterns, and microcopy — and shipped a working MVP.
AI-Assisted Development
I don’t write production code manually. I used AI-assisted development deliberately: I wrote detailed specs and behaviours, defined the data model to support the UX, had the AI implement, and then I reviewed and iterated through real usage and QA. I treated the AI like a development partner: I directed the work, I controlled quality, and I owned the product decisions.
Constraints I designed around
- Adoption friction is the enemy. If capture is even slightly annoying, people stop.
- Retrieval must be obvious and fast. If users can’t find the “why” quickly, trust collapses.
- Sharing is a multiplier. A private log is helpful; a stakeholder-ready narrative is transformative.
- Trust is a feature. Even an MVP needs credible boundaries (privacy, revocable sharing).
What I set out to prove
If capture is lightweight and structured, people will log turning points.
If the default mental model is chronological, recall improves versus folders.
If the structure matches how product work evolves, blank-page anxiety drops.
If sharing is one step, narratives escape the tool and reduce re-explaining.
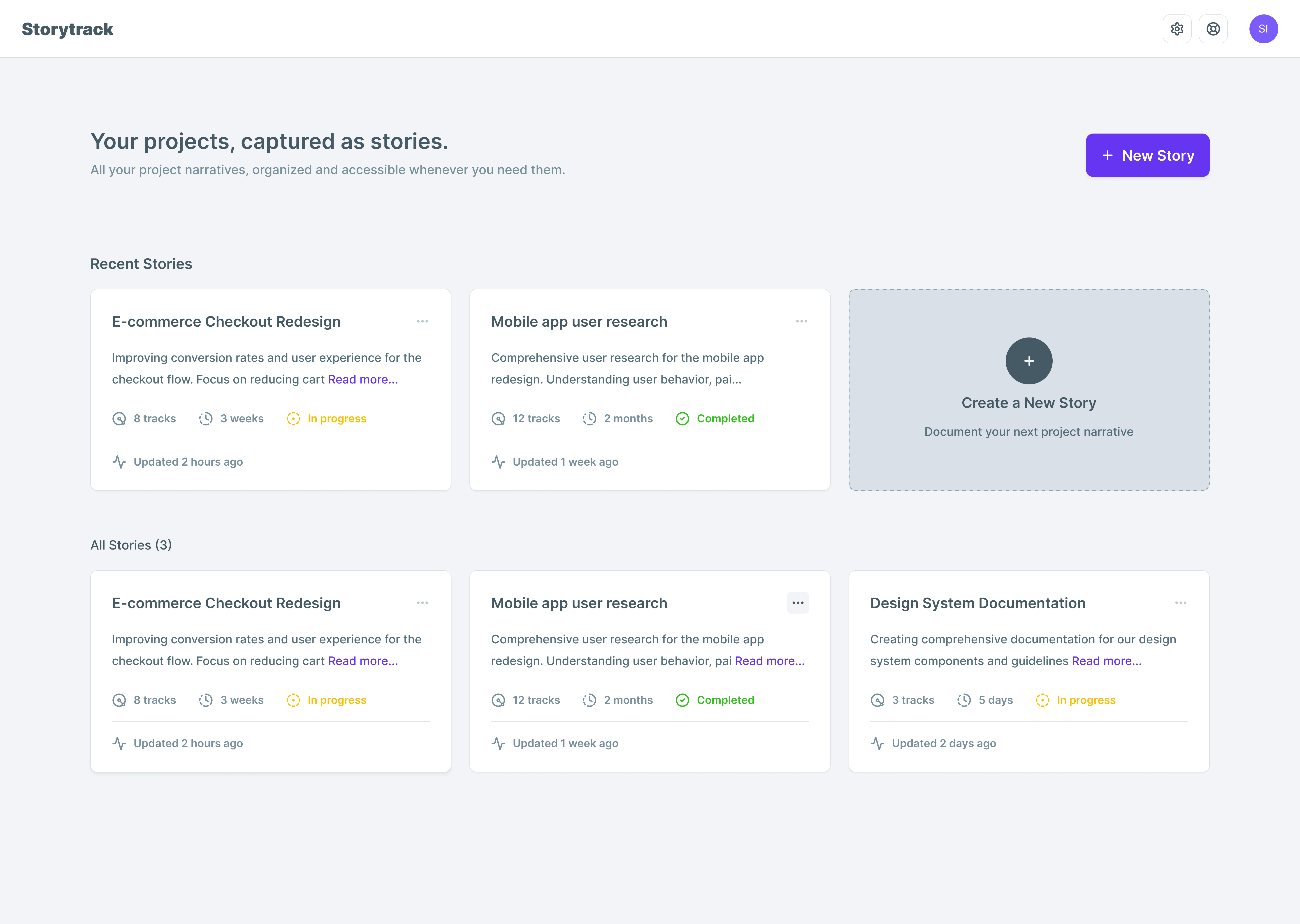
The solution (what I shipped)
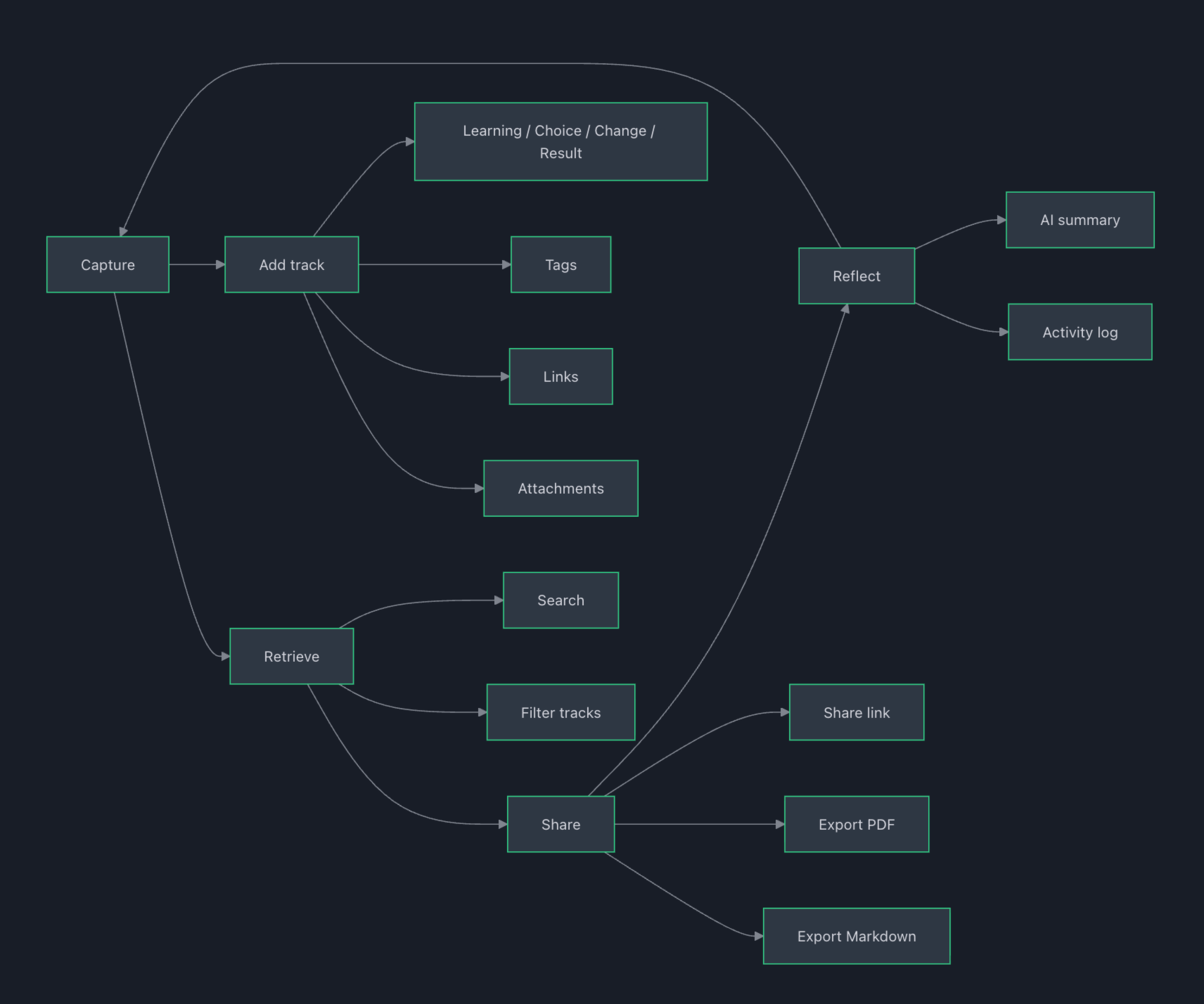
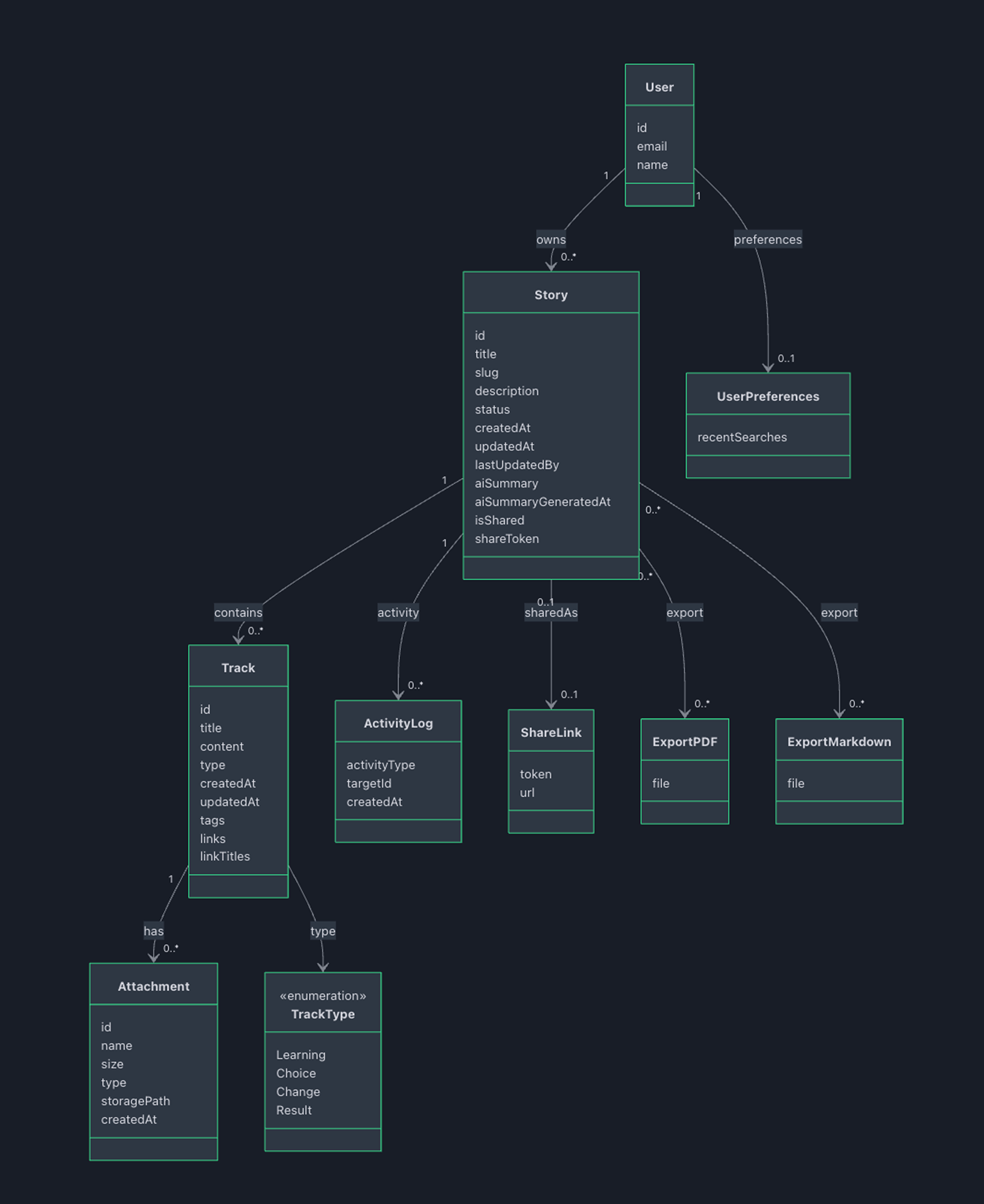
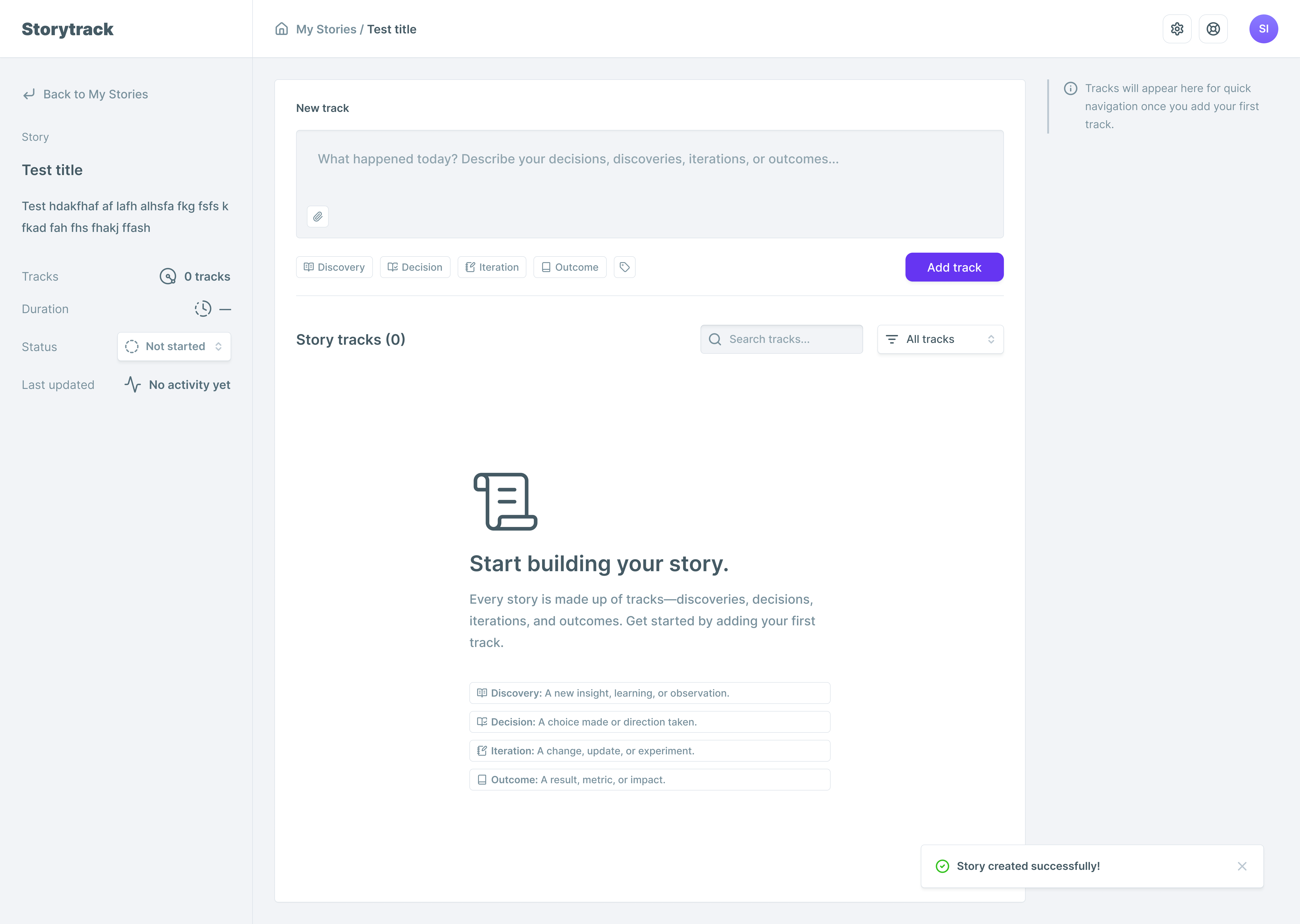
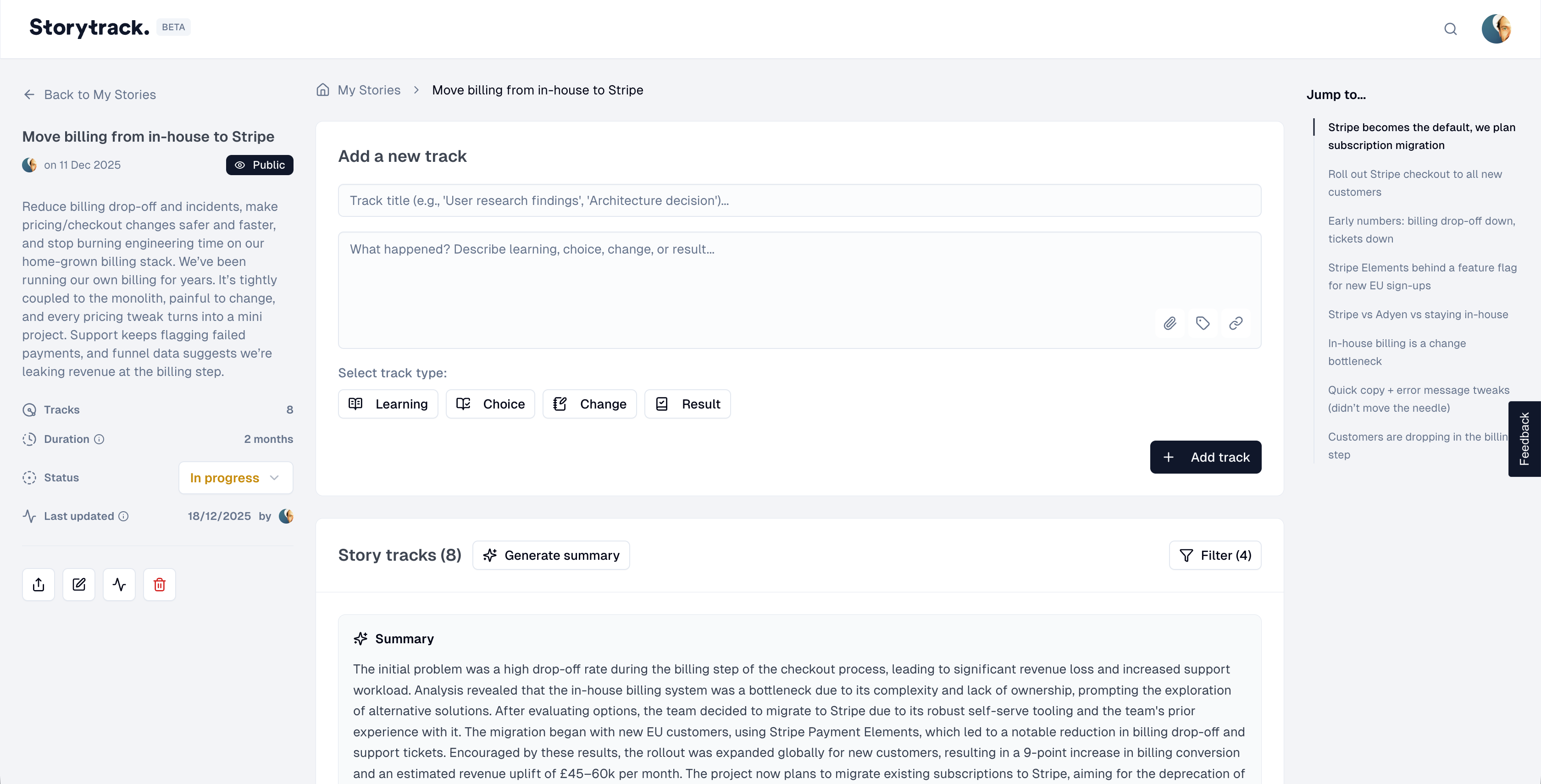
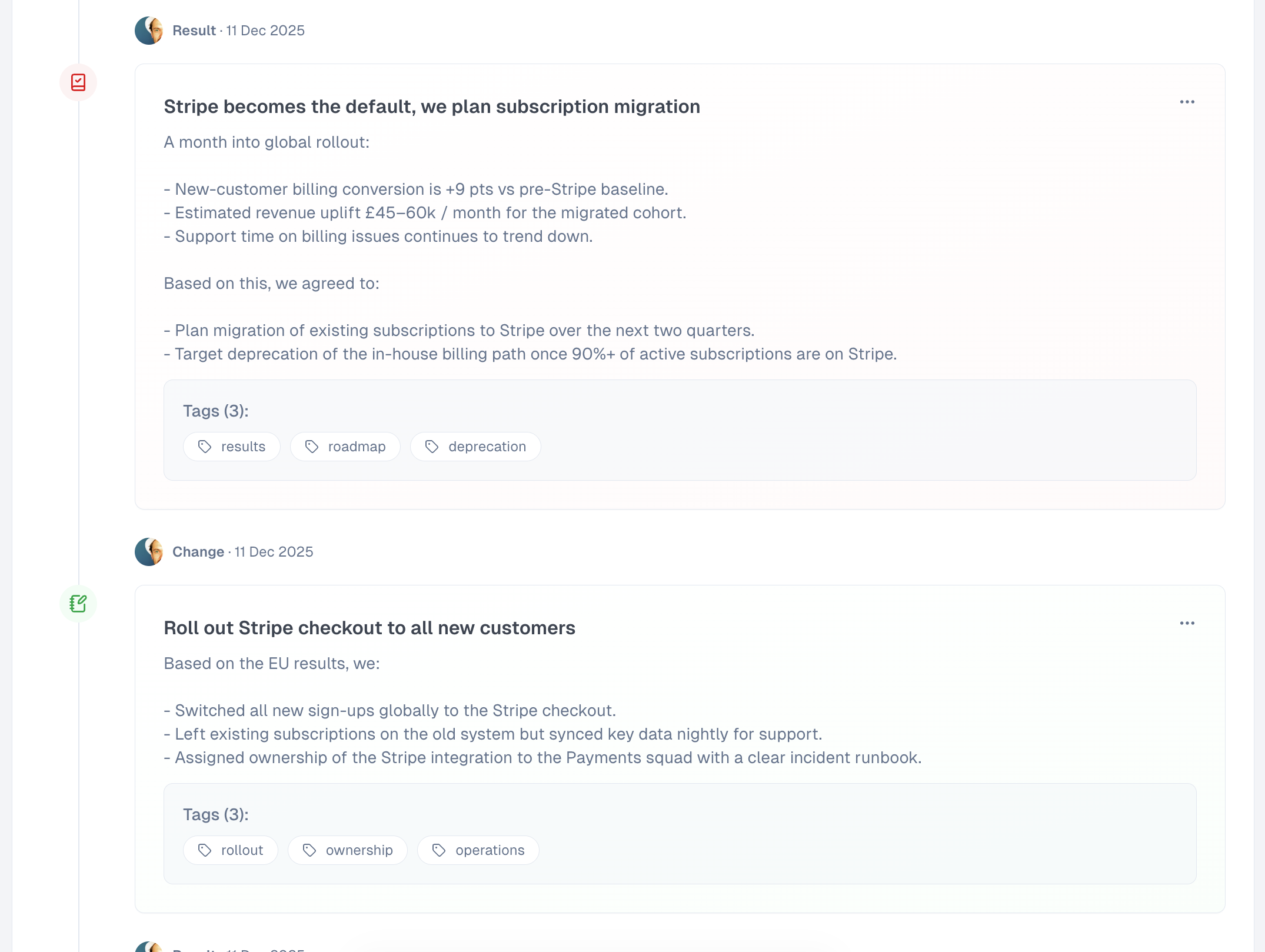
Stories and Tracks
A Story is a project/initiative narrative over time. A Track is a turning point captured at a moment in time.
I constrained Tracks to four types:
This is the core product decision: structure that’s strict enough to be scannable, but light enough to not feel like process theatre.
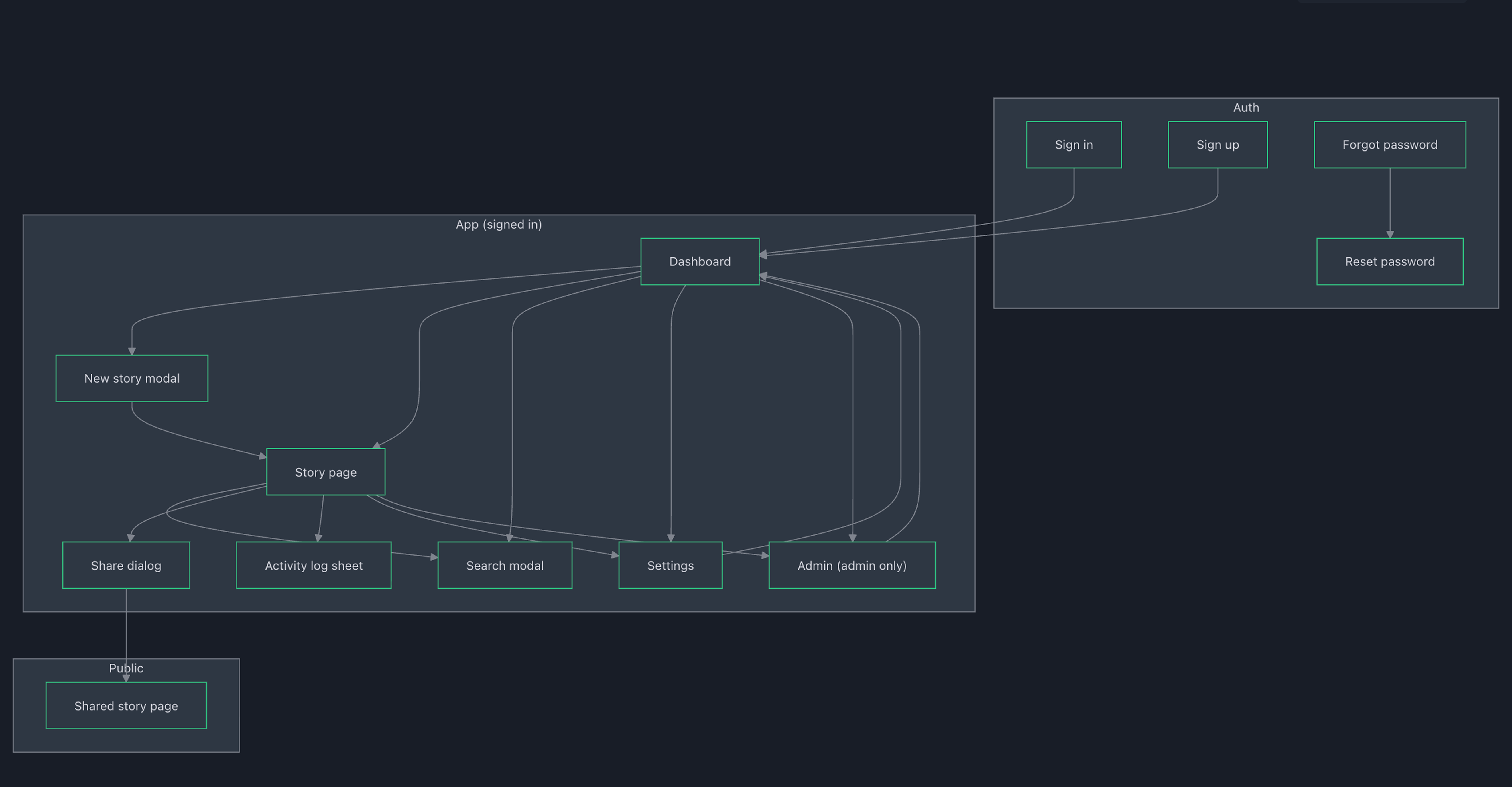
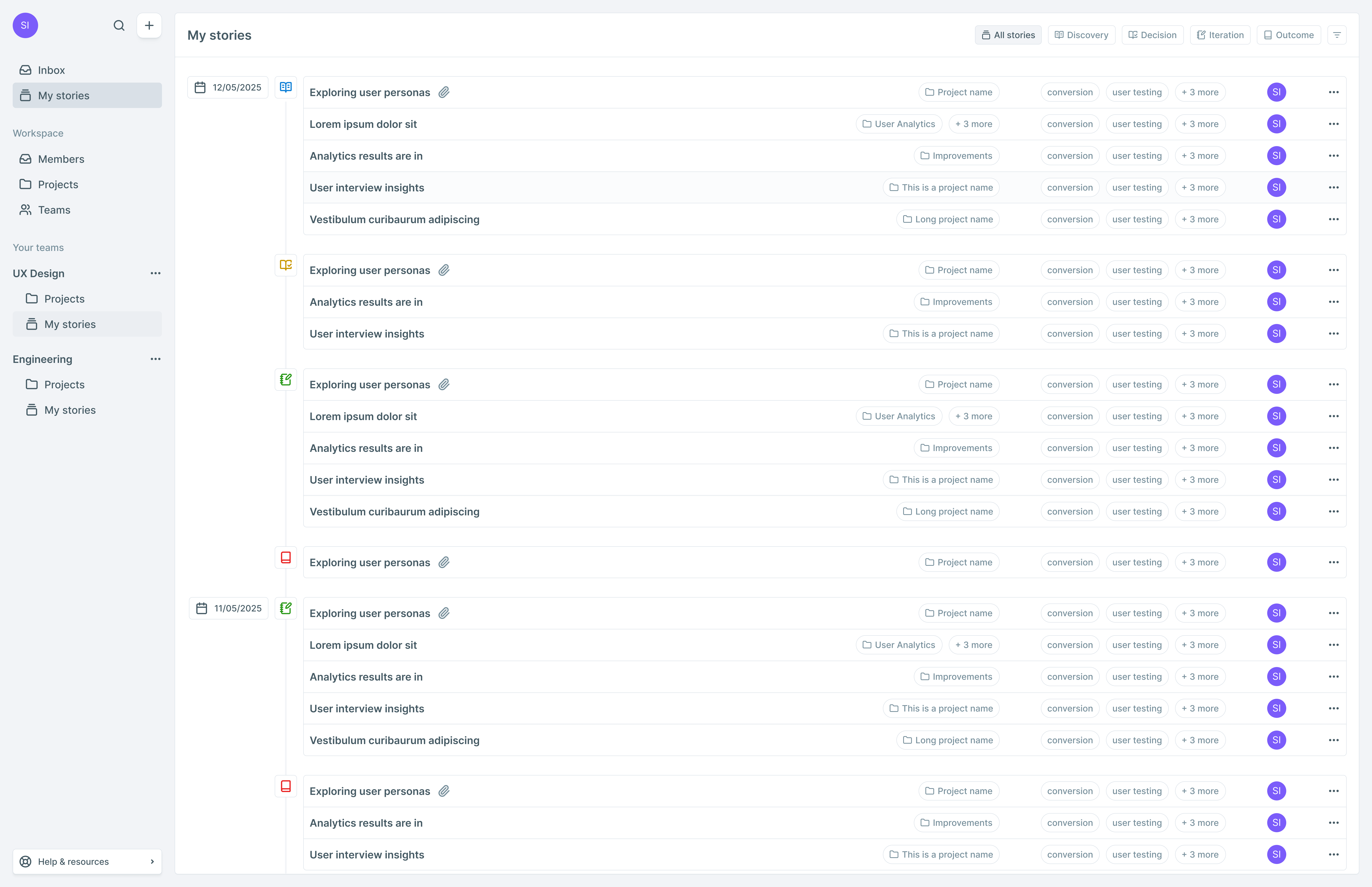
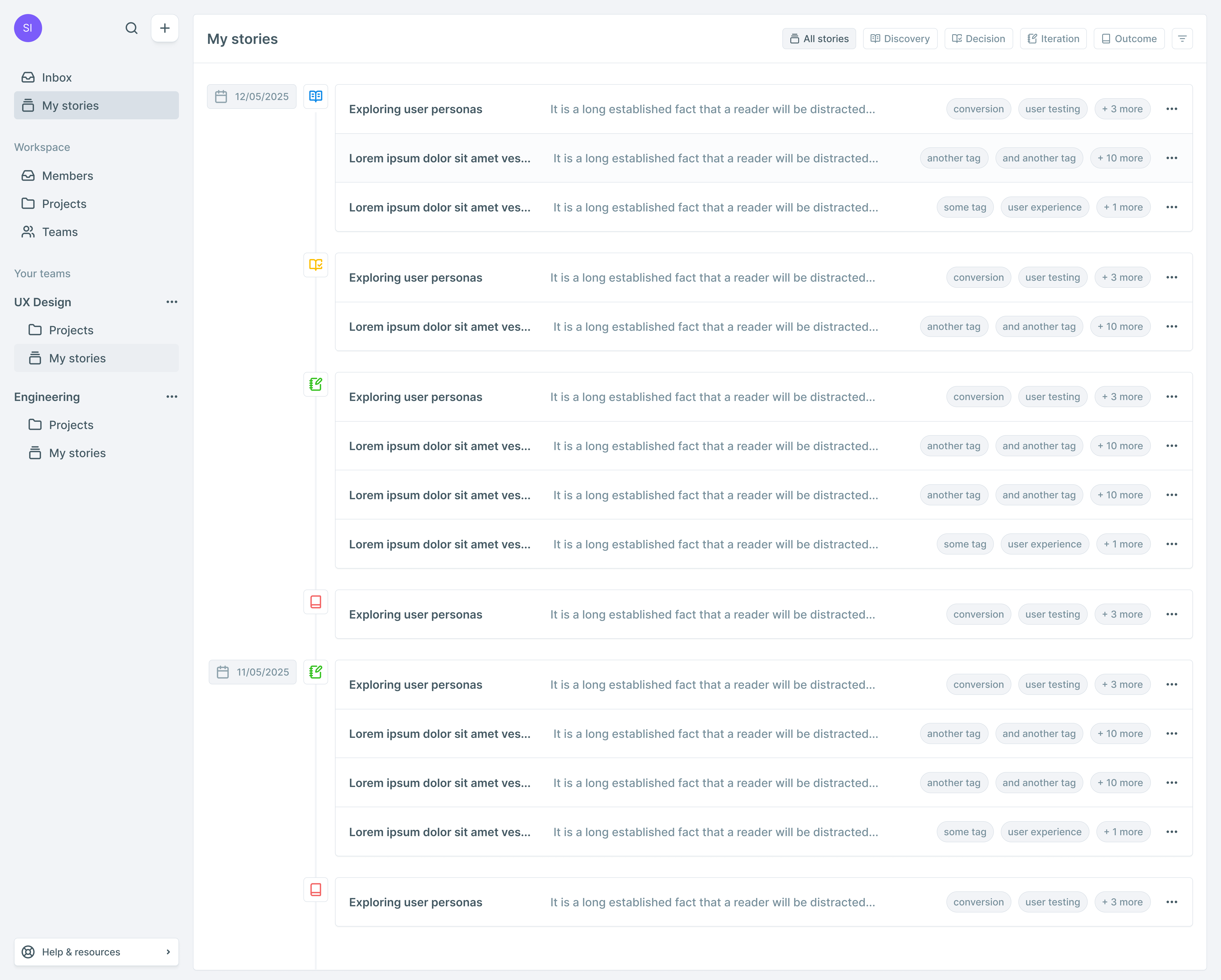
Timeline-first
The story page is designed for two modes: Authoring (minimal friction) and Reading (scan narrative, filter by type). A document-first tool asks you to write a summary of reality. A timeline-first tool makes sequence and causality visible by default.
Optional metadata
Each track supports tags, links, and attachments — but none are required. The MVP track is just type + title + a few lines. Metadata is there for credibility when needed, not as a mandatory ritual.
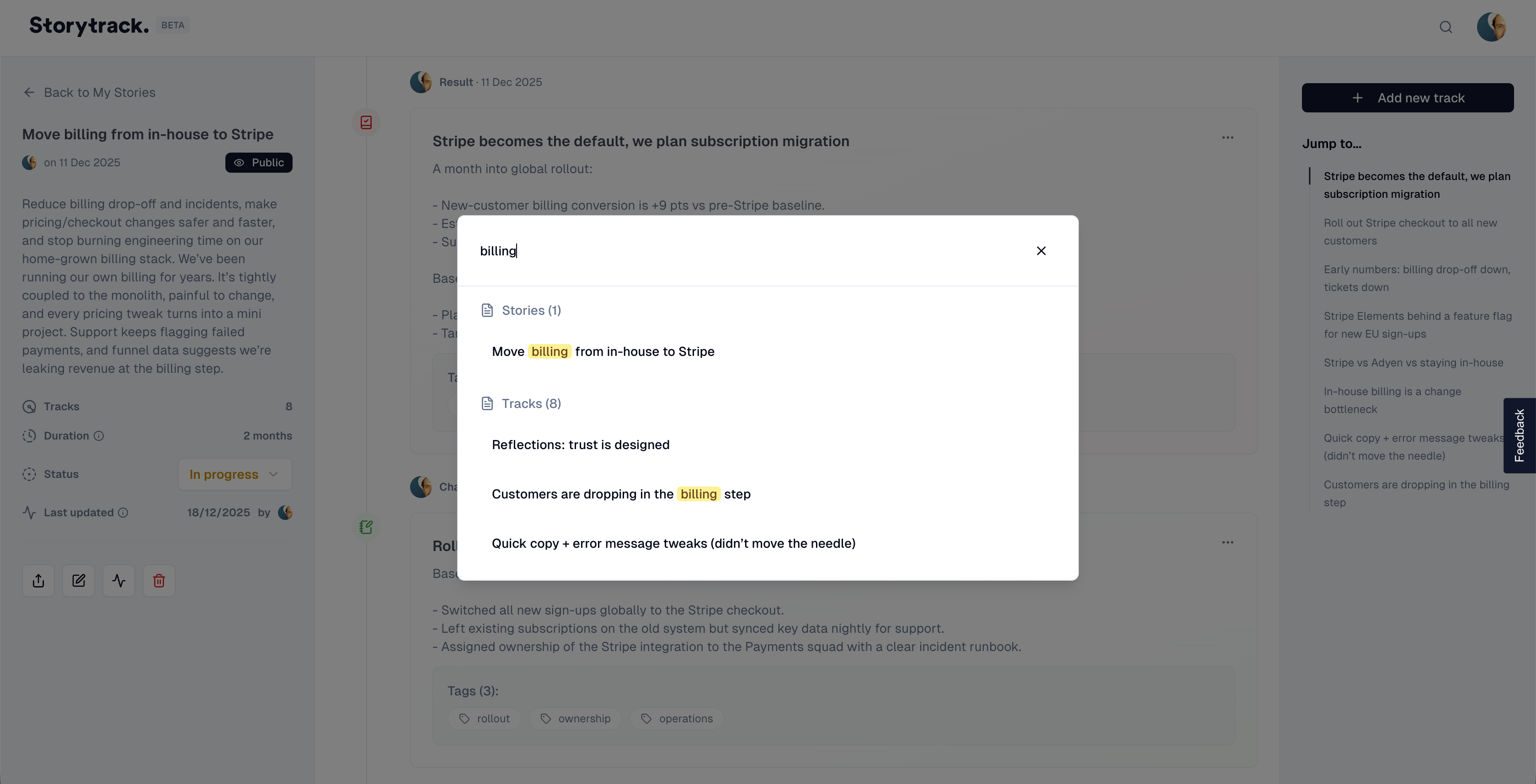
Search as a "trust feature"
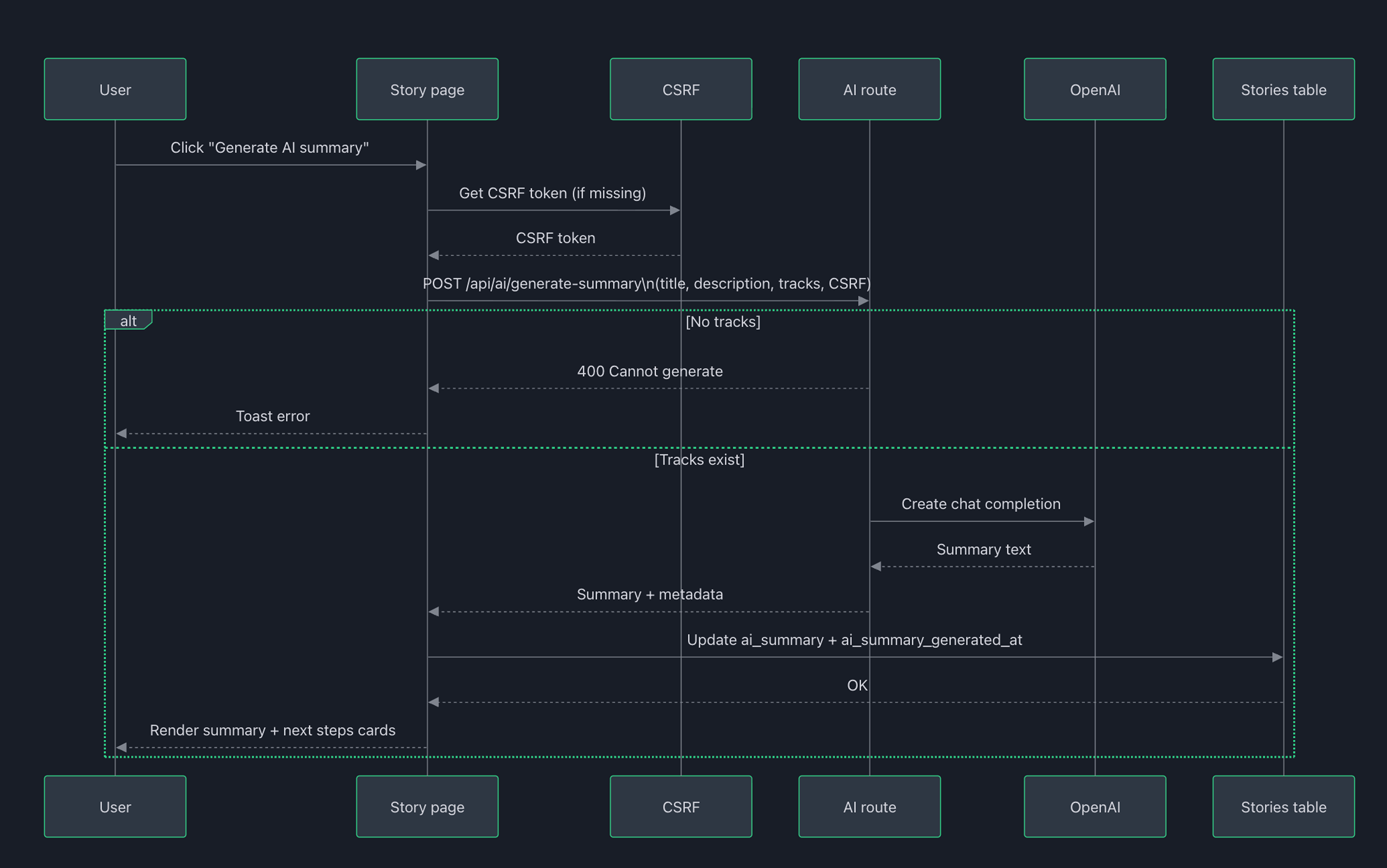
If someone asks "didn't we already decide this?", the product needs to answer immediately. I treated global search (Cmd+K) as core: accessible from anywhere, searching across stories/tracks/tags.
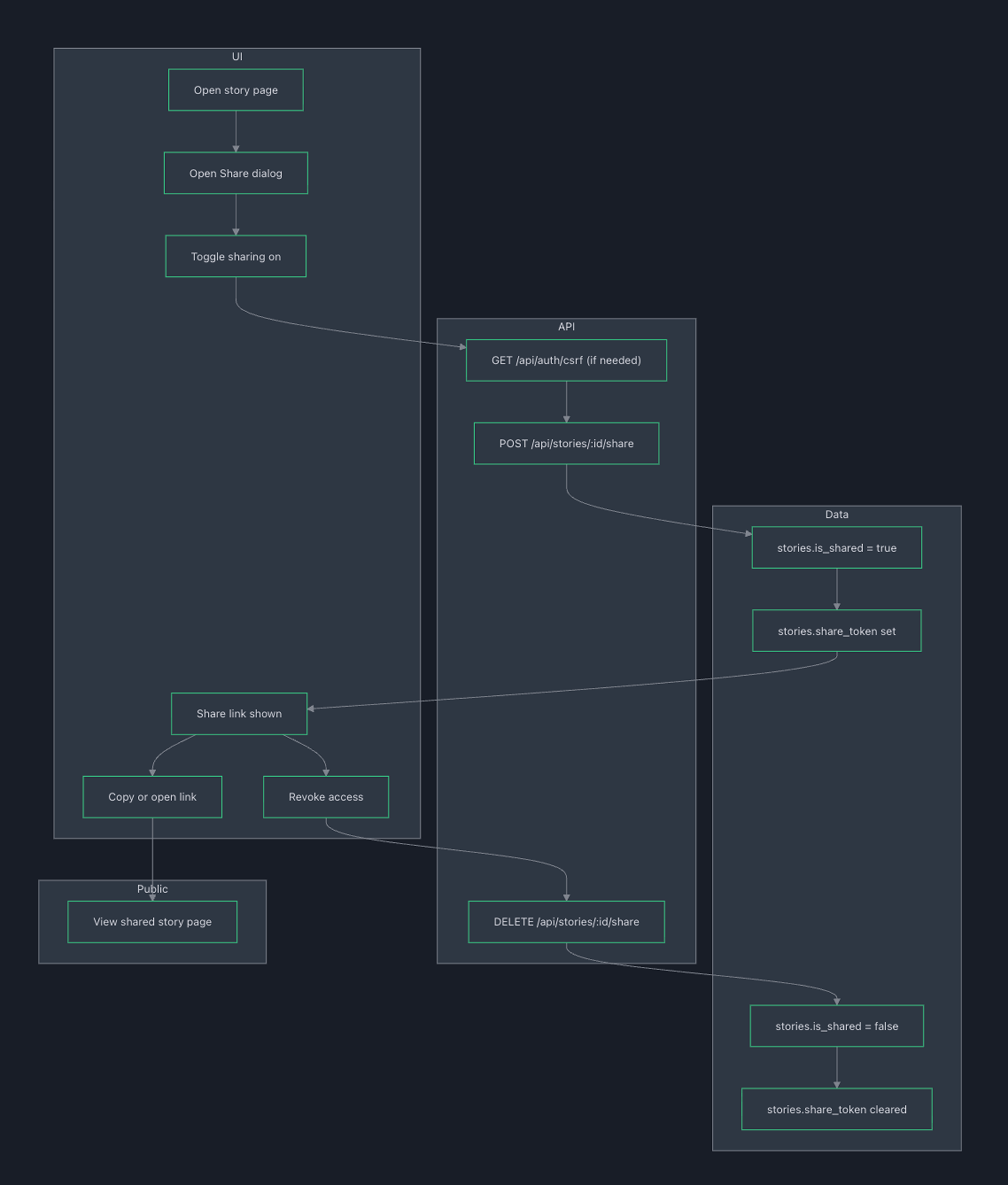
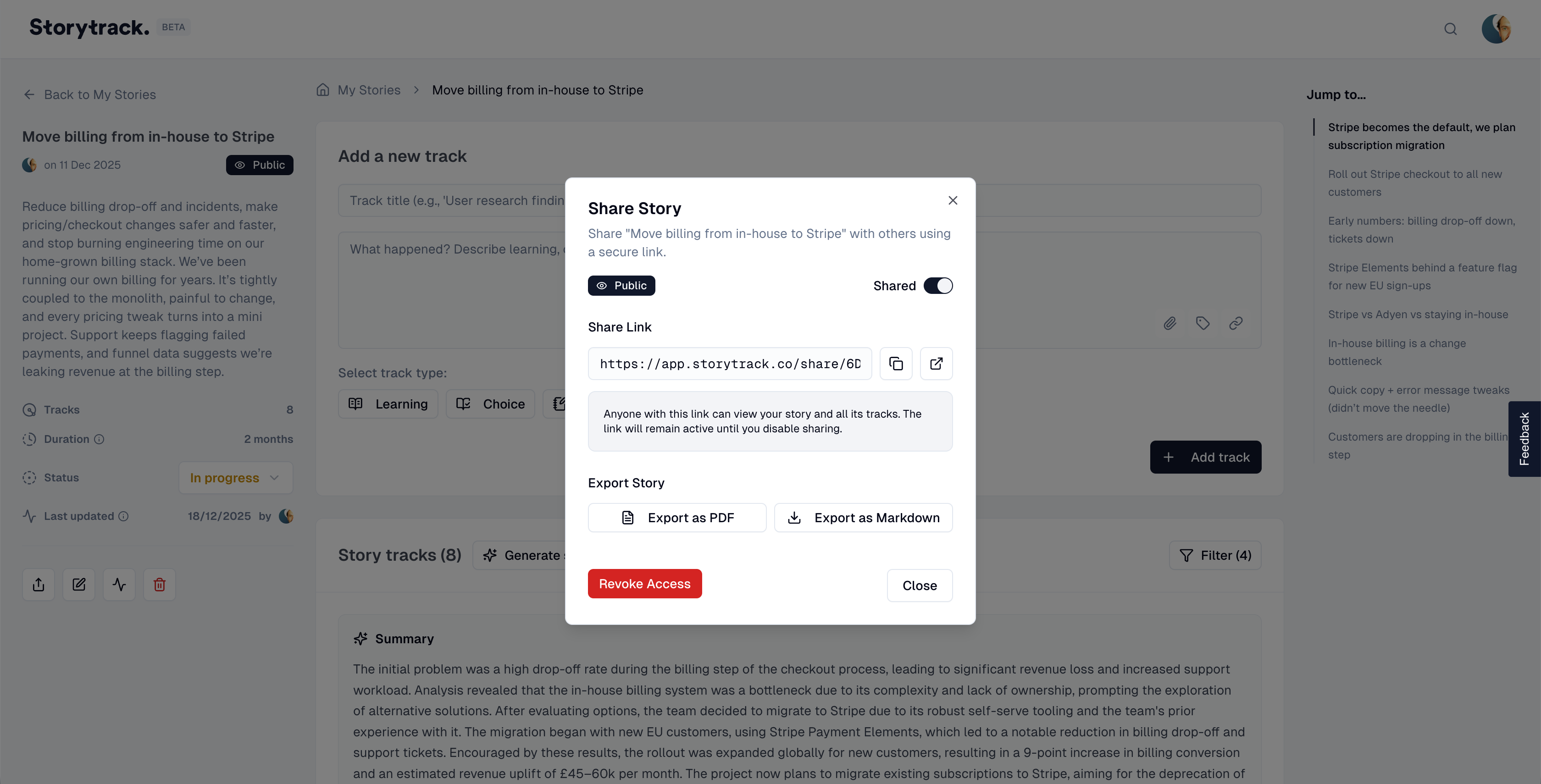
Sharing that respects reality
Stakeholders often won’t have accounts. Storytrack supports a simple model: generate a tokenised public link (read-only) that can be revoked. This satisfies the "stakeholder needs access" and "team needs control" constraints simultaneously.
AI summary
I positioned AI as assistive, not central. It generates a concise narrative recap from existing tracks, helping new joiners get up to speed without reading every entry. It's gated (only on populated stories) and persisted.
Visuals
Personas





Flows and Diagrams
Early Exploration
Live App
Product decisions and trade-offs
- Retrieval depends on causality.
- Sequence shouldn’t be something the author has to explain manually.
- Less flexibility for people who want arbitrary categorisation.
- Reduces blank-page friction.
- Makes narratives legible for people who weren’t there.
- Some entries don’t fit perfectly; classification friction is real.
- Retrieval must beat the urge to re-litigate.
- Early search is pragmatic rather than a "perfect knowledge graph".
- Stakeholder reality demands access without onboarding.
- Trust requires an off-switch.
- "Possession of link" is the access model (less granular).
- Adoption fails on friction, not on missing features.
- Shipped fewer "enterprise" features in v1.
What shipped (MVP scope)
Learnings & What's Next
"The biggest risk isn’t features — it’s behaviour change."
Learnings
If Storytrack feels like admin, usage decays. The product must pay users back quickly through retrieval and shareability.
Next Priorities
- Comprehension testing
Can people retrieve key decisions faster than in Confluence? - Guided capture
Lightweight prompts to reduce ambiguity. - Collaboration + permissions
Move from single-author to shared ownership safely. - Better retrieval
Server-side search, ranking, semantic linking.